This paper proposes a frequency method to
estimate the state open or closed of eye and
mouth and to detect associated motion events
such as blinking and yawning. The context of
that work is the detection of hypovigilence
state of a user such as a driver, a pilot... In
[1] we proposed a method for motion
detection and estimation which is based on the
processing achieved by the human visual
system.
The motion analysis algorithm the filtering
step occurring at the retina level and the
analysis done at the visual cortex level. This
method is used to estimate the motion of eye and
mouth: blinking are related to fast vertical
motion of the eyelid and yawning is related to
large vertical mouth opening. The detection of
the open or closed state of the feature is based
on the analysis of the total energy of the image
at the output of the retina filter: this energy
is higher for open features.
The absolute level of energy associated to a
specific state being different from a person to
another and for different illumination
conditions, the energy level associated to each
state open or closed is adaptive and is updated
each time a motion event (blinking or yawning)
is detected. No constraint about motion is
required. The system is working in real time and
under all type of lighting conditions since the
retina filtering is able to cope with
illumination variations. This allows to estimate
blinking and yawning frequencies which are clues
of hypovigilance.
Introduction The aim of the presented
work is the development of a real time algorithm
for hypovigilence analysis. The degree of
vigilance of a user can be related to the state
open or closed of his eyes and mouth and to the
frequency of his blinkings and yawnings. Work
about eye blinks detection is generally based on
temporal image derivative (for motion detection)
followed by image binarization analysis
[2].
Also, feature point tracking on eyes and
mouth is used to detect open / closed state and
motion [3]. All these methods are based
on spatial analysis of the eye/mouth region,
they are sensitive to image noise and generally
require a sufficient number of pixels to be
accurate. Moreover, these methods often require
morphological operations to avoid false blink
detections generated by global head motion.
Other methods can be used such as one based on
«second order change» [4] but
they always need binarization and thresholding,
the choice of the threshold being of critical
influence on the results. Work on mouth shape
detection is generally based on lips
segmentation: work with lip models such as
[5] use color and edge information but
these methods are sensitive to lighting and
contrast conditions.
Other methods such as parametric curves
[6] has been studied. Recently,
statistical model approaches such as active
shape and appearance models for example [7,
8] have been proposed and give accurate
results for lips segmentations. Nevertheless all
these methods cannot give information on the
mouth state. In the case of mouth motion
detection, lips segmentation or feature point
tracking [9] can be used but these
methods require much processing power and yield
to a mouth shape estimation rather than yawnings
detection. In this paper, we use the spectral
analysis method described in [1] that
will allow the detection of eye and mouth states
and blink/yawning with the same method. It
involves a spatio-temporal filter modelling the
human retina and dedicated to the detection of
motion stimulus. It is used to estimate the
motion of eye and mouth: blinking are related to
fast vertical motion of the eyelid and yawning
is related to large vertical mouth opening.
The detection of the open or closed state of
the feature is based on the analysis of the
total energy at the output of the retina filter:
this energy is higher for open features. In
section 2 the general principle of the motion
estimation method is explained and the
properties of the motion estimator are given
(see [1] for more details). .. Section 3
describes the proposed method to detect eye and
mouth motions events (blinks and yawnings) and
section 4 describes how to detect the open or
closed feature state which is associated to an
adaptive updating of the related level of energy
of the image spectrum. Section 5 presents some
results.
double cliquez sur la video pour
démarrer
Vidéo
illustrant le système de détection
d'ouverture/fermeture de bouche et donne une
courbe d'illustration qui montre comment
à partir du critère
analysé, il est possible de distinguer
les états, ouverts/fermés de la
bouche, mais aussi les actions, (statique),
parole et baillement.
La vidéo
montre le fonctionnement normal du
système (il s'adapte à la
situation d'analyse sans rien connaitre au
début, donc quelques erreurs au
début de la séquence et
après le système est
initialisé et fonctionne)
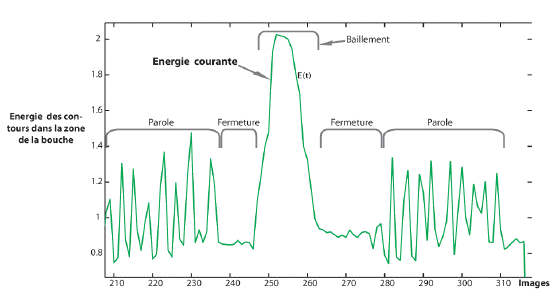
La courbe
d'illustration montre l'évolution
temporelle du critère d'analyse. Ce
critère est une énergie à
chaque instant liée à la
quantité de contours dans la zone
d'analyse (la bouche). on observe sur cette
illustration que l'évolution temporelle
de ce critère permet d'identifier sans
hésitation un bâillement par
rapport aux autres cas de figure. (forte et
durable élévation de
l'énergie lors de l'ouverture et de
même lors de la fermeture lors du
bâillement.
...
Mouth state and yawning
detection
The same method is applied to mouth yawning
detection. Figure 8 shows the results on a
sequence in which the mouth exaggerates its open
and closed state from frame 1 to frame 300, is
closed from frame 301 to frame 500, and opens /
closes normally after frame 500 because of
natural speech. We can see that the algorithm
self adjusts its parameters HighEnergyLevel and
LowEnergyLevel before frame 200, this is the
initialization period where each mouth state is
performed more than 0.5 second by the user in
order to correctly initialize these parameters.
Then the algorithm updates them with respect to
the evolution of the OPL output spectral
energy.
The LowEnergyLevel corresponds to closed
mouth because the closed lips generate a lower
quantity of contours. The HighEnergyLevel
corresponds to open mouth which let appear tooth
and/or internal mouth details or a black area
that generate high energy contours with the lips
frontier. Note that during the stable
open/closed mouth periods, the HighEnergyLevel
and LowEnergyLevel values are adjusted and when
the speech periods happen (from frame 500 to the
end), these levels are no more or few updated.
This allows the correct detection of the mouth
state even in case of fast mouth shape variation
that occurs during speaking.
PERFORMANCES AND APPLICATION The
performances of this facial feature state and
motion event detector have been evaluated in
various test condition: it detects states and
movements events up to 99% success in standard
office lighting conditions with the focused
object occupying from 60% to 100% of the
captured frame (currently 100*100 pixels). In
low light conditions or noisy captured frames
(Gaussian white noise of variance 0.04), the
algorithm is able to detect the motion events
and states with 80% success.
Moreover, even if the algorithm is 'lost' at
a moment, since it is adaptive, it automatically
corrects its energy levels and works fine when
the sequence returns to normal conditions. The
algorithm works in real time, reaching up to 80
frames per second on a standard PC desktop
Pentium 4 running at 3.0Ghz on which a webcam is
installed. The algorithm automatically adjusts
its parameters during the analysis. This
proposed approach is inspired from the
capacities of the human visual system which is
adaptive and is able to cope with various
illumination and motion conditions.
Conclusion A real time method for
facial feature state and motion events detection
has been proposed, it works with eye and mouth
in the same way. The algorithm inspired from the
biological model of the human visual system
shows its efficiency in terms of motion
detection and analysis: the use of the retina
filter prepares the data and yields to a
spectrum easy to analyze. The proposed algorithm
proves its efficiency to estimate the open or
closed state of eye and mouth and the frequency
of blinking and yawning. This is well suited for
the analysis of a user vigilance. The
performances of the algorithm on video sequences
of a car driver are under study.
Iu. N. Bordiushkov Biull
Eksp Biol Med
1958;46(7):885-887
References
[1] A. Benoit, A. Caplier. "Motion
estimator inspired from biological model for
head motion interpretation " WIAMIS 2005,
Montreux, Switzerland, April 2005
[2] J. Coutaz, F. Berard, and J. L.
Crowley. "Coordination of perceptual processes
for computer mediated communication". In Proc.
of 2nd Intl Conf. Automatic Face and Gesture
Rec., pages 106--111, 1996.
[3] P. Smith, M. Shah, N. da Vitoria
Lobo, "Determining Driver Visual Attention with
One Camera", Accepted forIEEE Transactions on
Intelligent Transportation Systems, 2004.
[4] D. Gorodnichy, "Towards
Automatic Retrieval of Blink- Based Lexicon for
Persons Suffered from Brain-Stem Injury Using
Video Cameras," Proceedings of the First IEEE
Computer Vision and Pattern Recognition (CVPR)
Workshop on Face Processing in Video.
Washington, District of Columbia, USA. June 28,
2004. NRC 47138.
[5] P. Delmas, N.Eveno, and M.
Lievin, "Towards Robust Lip Tracking",
International Conference on Pattern Recognition
(ICPR'02),Québec City, Canada, August
2002
[6] N.Eveno, A. Caplier, and P-Y
Coulon, "Jumping Snakes and Parametric Model for
Lip Segmentation", International Conference on
Image Processing, Barcelona, Spain, September
2003
[7] T. F. Cootes. "Statistical
models of appearance for computer vision"
[8] P. Gacon, P.-Y. Coulon, G.
Bailly. "Statistical Active Model for Mouth
Components Segmentation", 2005 IEEE
International Conference on Acoustics, Speech
and Signal Processing (ICASSP'05), Philadelphia,
USA, 2005.
[9] Y. Tian, T. Kanade, J.F. Cohn
"Robust Lip Tracking by Combining Shape, Color
and Motion" Proc. of the 4th Asian Conference on
Computer Vision (ACCV'00), January, 2000
[10] W.H.A. Beaudot, "The neural
information processing in the vertebrate retina:
A melting pot of ideas for artificial vision",
PhD Thesis in Computer Science, INPG (France)
december 1994
[11] J. Ritcher&S.Ullman. "A
model for temporal organization of X- and Y-type
receptive fields in the primate retina".
Biological Cybernetics, 43:127-145,1982.
[12] Barron J.L., Fleet D.J. and
Beauchemin S.S., "Performance of Optical Flow
Techniques", International Journal of Computer
Vision, Vol. 12, No. 1, pp. 43-77, 1994.
Monitoring
mouth movement for driver fatigue or distraction
with one camera
Wang Rongben Guo Lie Tong Bingliang Jin
Lisheng
Transp. Coll., Jilin Univ.,
Changchun, China
Intelligent Transportation
Systems, 2004. Proceedings. The 7th
International IEEE Conference (3-6 Oct. 2004;314
-319)
Abstract This paper proposed to
locate and track a driver's mouth movement using
a dashboardmounted CCD camera. Study on
monitoring and recognizing a driver's
yawning fatigue state and distraction
state due to talking or conversation. Firstly
determining the interest of area for mouth by
detecting face using color analysis, then
segmenting skin and lip pixels by fisher
classifier, and detecting driver's mouth and
extracting lip features by connected component
analysis, tracking driver's mouth via Kalman
filtering in real time. Taking the mouth
region's geometric features to make up an
eigenvector as the input of a BP ANN, then we
acquire the BP ANN output of three different
mouth states that represent normal, yawning or
talking state respectively. The experiment
results show that this new method can inspect
the driver's mouth region accurately and
quickly, and gives a warning sign when it find
driver's yawning fatigue state and distraction
state due to talking or conversation.
Yawning
detection for determining driver drowsiness
Tiesheng Wang Pengfei Shi
Inst. of Image Process.
& Pattern Recognition, Shanghai Jiao Tong
Univ., China
VLSI Design and Video
Technology, 2005. Proceedings of 2005 IEEE
International Workshop (28-30 May
2005:373-376)
Abstract A system aiming at detecting
driver drowsiness or fatigue on the basis of
video analysis is presented. The focus of this
paper is on how to extract driver
yawning. A real time face detector is
implemented to locate driver's face region.
Subsequently, Kalman filter is adapted to track
face region. Further, mouth window is localized
within face region and degree of mouth openness
is extracted based on mouth features to
determine driver yawning in video. The
system will reinitialize when occlusion or
miss-detect on happen. Experiments are conducted
to evaluate the validity of the described
method.
Determining
driver visual attention with one camera
Smith, P. Shah, M. da Vitoria Lobo, N.
Dept. of Comput. Sci.,
Central Florida Univ., Orlando, FL, USA
Abstract This paper presents a system
for analyzing human driver visual attention. The
system relies on estimation of global motion and
color statistics to robustly track a person's
head and facial features. The system is fully
automatic, it can initialize automatically, and
reinitialize when necessary. The system
classifies rotation in all viewing directions,
detects eye/mouth occlusion, detects eye
blinking and eye closure, and recovers the three
dimensional gaze of the eyes. In addition, the
system is able to track both through occlusion
due to eye blinking, and eye closure, large
mouth movement, and also through occlusion due
to rotation. Even when the face is fully
occluded due to rotation, the system does not
break down. Further the system is able to track
through yawning, which is a large local mouth
motion. Finally, results are presented, and
future work on how this system can be used for
more advanced driver visual attention monitoring
is discussed.
Comparison
of impedance and inductance ventilation sensors
on adults during breathing, motion, and
simulated airway obstruction
Abstract The goal of this study was
to compare the relative performance of two
noninvasive ventilation sensing technologies on
adults during artifacts. The authors recorded
changes in transthoracic impedance and
cross-sectional area of the abdomen (abd) and
ribcage (rc) using impedance pneumography (IP)
and respiratory inductance plethysmography (RIP)
on ten adult subjects during natural breathing,
motion artifact, simulated airway obstruction,
yawning, snoring, apnea, and coughing.
The authors used a pneumotachometer to measure
air flow and tidal volume as the standard. They
calibrated all sensors during natural breathing,
and performed measurements during all maneuvers
without changing the calibration parameters. No
sensor provided the most-accurate measure of
tidal volume for all maneuvers. Overall, the
combination of inductance sensors [RIP(sum)
] calibrated during an isovolume maneuver
had a bias (weighted mean difference) as low or
lower than all individual sensors and all
combinations of sensors. The IP(rc) sensor had a
bias as low or lower than any individual sensor.
The cross-correlation coefficient between
sensors was high during natural breathing, but
decreased during artifacts. The cross
correlation between sensor pairs was lower
during artifacts without breathing than it was
during maneuvers with breathing for four
different sensor combinations. The authors
tested a simple breathdetection algorithm on all
sensors and found that RIP(sum) resulted in the
fewest number of false breath detections, with
sensitivity of 90.8% and positive predictivity
of 93.6%
Public
speaking in virtual reality: facing an audience
of avatars
Computer Graphics and
Applications, IEEE 1999;19(2):6-9
Abstract What happens when someone
talks in public to an audience they know to be
entirely computer generated-to an audience of
avatars? If the virtual audience seems
attentive, wellbehaved, and interested, if they
show positive facial expressions with
complimentary actions such as clapping and
nodding, does the speaker infer correspondingly
positive evaluations of performance and show
fewer signs of anxiety? On the other hand, if
the audience seems hostile, disinterested, and
visibly bored, if they have negative facial
expressions and exhibit reactions such as
head-shaking, loud yawning, turning away,
falling asleep, and walking out, does the
speaker infer correspondingly negative
evaluations of performance and show more signs
of anxiety? We set out to study this question
during the summer of 1998. We designed a virtual
public speaking scenario, followed by an
experimental study. We wanted mainly to explore
the effectiveness of virtual environments (VEs)
in psychotherapy for social phobias. Rather than
plunge straight in and design a virtual reality
therapy tool, we first tackled the question of
whether real people's emotional responses are
appropriate to the behavior of the virtual
people with whom they may interact. The project
used DIVE (Distributive Interactive Virtual
Environment) as the basis for constructing a
working prototype of a virtual public speaking
simulation. We constructed as a Virtual Reality
Modeling Language (VRML) model, a virtual
seminar room that matched the actual seminar
room in which subjects completed their various
questionnaires and met with the
experimenters.
Hidden
markov model based dynamic facial action
recognition
Arsic, D. Schenk, J. Schuller, B. Wallhoff,
F. Rigoll, G.
Technische Universität
München, Institute for Human Machine
Communication, Arcisstrasse 16, 80333
München, Germany.
Image Processing, 2006 IEEE
2006: 673-676
Abstract Video based analysis of a
persons' mood or behavior is in general
performed by interpreting various features
observed on the body. Facial actions, such as
speaking, yawning or laughing are
considered as key features. Dynamic changes
within the face can be modeled with the well
known Hidden Markov Models (HMM). Unfortunately
even within one class examples can show a high
variance because of unknown start and end state
or the length of a facial action. In this work
we therefore perform a decomposition of those
into so called submotions. These can be robustly
recognized with HMMs, applying selected points
in the face and their geometrical distances.
Additionally the first and second derivation of
the distances is included. A sequence of
submotions is then interpreted with a dictionary
and dynamic programming, as the order may be
crucial. Analyzing the frequency of sequences
shows the relevance of the submotions order. In
an experimental section we show, that our novel
submotion approach outperforms a standard HMM
with the same set of features by nearly 30%
absolute recognition rates
A
non-rigid motion estimation algorithm for yawn
detection in human drivers
Mohanty, M, Mishra, A, Routray, A.
Int. J. Computational Vision
and Robotics
2009;1(1):89-109
This work focuses on the estimation of
possible fatigue or drowsiness by detecting the
occurrence of yawns with human drivers. An image
processing technique has been proposed to
analyse the deformation occurring on driver's
face and accurately identify the yawn from other
types of mouth opening such as talking and
singing. The algorithm quantifies the degree of
deformation on lips when a driver yawns.
The image processing methodology is based on
study of non-rigid motion patterns on 2D images.
The analysis is done on a temporal sequence of
images acquired by a camera. A shape-based
correspondence of templates on contours of a
particular region is established on the basis of
curvature information. The shape similarity
between the contours is analysed, after
decomposing with wavelets at different
levels.
Finally, the yawn is correlated with
fatigue-induced behaviour of drivers on
simulaton
Détécter
les bâillements du chauffeur
Cette équipe de recherche indienne
essaie de mettre au point un détecteur de
bâillements qui pourrait réduire le
nombre d'accidents de la route causés par
la somnolence d'un conducteur au volant.
En cours d'élaboration, cette
technologie indo-américaine est
intégrée à
l'intérieur de l'automobile, ont
indiqué les concepteurs, dont les travaux
sont publiés dans The International
Journal of Computational Vision and
Robotics.
Le nouveau système est
constitué d'une caméra et d'un
logiciel qui analyse instantanément les
images du visage, captées à
intervalles réguliers. En plus d'analyser
les modifications du visage du chauffeur,
l'appareil distingue les bâillements des
autres mouvements faciaux, comme les actions de
sourire, de discuter ou de chanter.
À partir du moment où le
conducteur pousse des bâillements, le
logiciel se met à calculer leur
fréquence. Si ces derniers se
répètent trop souvent, un signal
d'avertissement est déclenché. Aux
États-Unis seulement,
100 000 accidents de la route sont
causés, chaque année, par la
fatigue d'un conducteur, selon la National
Highway Traffic Safety
Administration (NHTSA).
De l'électrode à la lentille :
au cours des dernières années,
d'autres systèmes de détection de
fatigue ont été mis au point.
Ceux-ci enregistraient notamment
l'activité du cerveau ou les pulsations
cardiaques. Les inventeurs du détecteur
de bâillements soutiennent que leur
système de caméra est moins
encombrant que ces appareils, souvent munis d'un
casque chargé d'électrodes devant
être porté par le conducteur.
En général, les conducteurs
ont tendance à sous-estimer leur fatigue
et les conséquences de celle-ci sur leur
disposition à conduire un
véhicule. En revanche, ils surestiment
leur capacité à combattre le
sommeil qui s'empare d'eux.
Multimodal
focus attention and stress detection and
feedback in an augmented driver
simulator
This paper presents a driver simulator,
which takes into account the information about
the user's state of mind (level of attention,
fatigue state, stress state). The user's state
of mind analysis is based on video data and
biological signals. Facial movements such as
eyes blinking, yawning, head rotations, etc.,
are detected on video data: they are used in
order to evaluate the fatigue and the attention
level of the driver. The user's
electrocardiogram and galvanic skin response are
recorded and analyzed in order to evaluate the
stress level of the driver. A driver simulator
software is modified so that the system is able
to appropriately react to these critical
situations of fatigue and stress: some audio and
visual messages are sent to the driver, wheel
vibrations are generated and the driver is
supposed to react to the alert messages. A
multi-threaded system is proposed to support
multi-messages sent by the different modalities.
Strategies for data fusion and fission are also
provided. Some of these components are
integrated within the first prototype of
OpenInterface: the multimodal similar
platform.
Introduction
The major goal of this project is the use of
multimodal signals and video processing to
provide an augmented user's interface for
driving. In this paper, we are focusing on
passive modalities. The term augmented here can
be understood as an attentive interface
supporting the user interaction. So far at the
most basic level, the system should contain at
least five components:
1. sensors for determining the user's state
of mind;
2. modules for features or data
extraction;
3. a fusion process to evaluate incoming
sensor information;
4. an adaptive user interface based on the
results of step 3;
5. an underlying computational architecture
to integrate these components.
In this paper, we address the following
issues:
• Which driver simulator to use?
• How to characterize a user's state of
fatigue or stress?
• Which biological signals to take into
account?
• What kind of alarms to send to the
user?
• How to integrate all these
pieces&emdash;data fusion and
fission mechanism?
• Which software architecture is the
most appropriate to
support such kind of integration?
A software architecture supporting real time
processing is the first requirement of the
project because the system has to be
interactive. A distributed approach supporting
multi-threaded server can address such needs. We
are focusing on stress and fatigue detection.
The detection is based on video information
and/or on biological information. From the video
data we extract relevant information to detect
fatigue states while the biological signals
provide data for stress detection. The following
step is the definition of the alarms to be
provided to the user. Textual and vocal messages
and wheel vibrations are considered to alert the
user. The rest of the paper is organized as
follows: first, we present the global
architecture of the demonstrator, then we
describe how it is possible to detect driver's
hypo-vigilance states by the analysis of video
data, then we present how to detect driver's
stress states by the analysis of some biological
signals. Finally the data fusion and fission
strategies are presented and the details about
the demonstrator implementation are given.
3 Hypo-vigilance detection based on
video data The state of hypo-vigilance (either
related to fatigue or inattention) is detected
by the analysis of video data. The required
sensor is a camera facing the driver. Three
indices are considered as hypo-vigilance signs:
yawning, head rotations and eyes closing for
more than 1 s.
3.1 Face detection In this paper, we
are not focusing on face localization. The face
detector should be robust (no error in face
localization) and should work in real time. We
chose to use the free toolbox MPT [5].
This face detector extracts a squarebounding box
around each face in the processed image. The MPT
face detector works nearly at 30 frames per
second for pictures of size 320 · 200
pixels, which is not the case of other face
detectors such as OpenCV [13] for
example.
3.2 Head motion analysis Once a
bounding box around the driver's face has been
detected, head motion such as head rotations,
eyes closing and yawning are detected using an
algorithm working in a way close to the human
visual system. In a first step, a filter coming
from the modeling of the human retina is
applied. This filter enhances moving contours
and cancels static ones. In a second step, the
FFT of the filtered image is computed in the log
polar domain as a modeling of the process
occurring in the primary visual cortex. Details
about the proposed method are described in
[1, 2]. As a result of retinal
filtering, noise and luminance variations are
attenuated and moving contours are enhanced. For
example on Fig. 2, after retina filter, all the
details are visible even in the darkest area of
the image Fig. 3.
The modeling of the primary visual cortex
consists of a frequency analysis of the spectrum
of the retina filters output in each region of
interest of the face: global head, eyes area and
mouth area only. In order to estimate the rigid
head rotations, the proposed method analyses the
spectrum of the retina filter output in the log
polar domain. It detects head motion events and
is able to extract its orientation (see [1,
3]). The main idea is that the spectrum
reports high energy only for the moving contours
perpendicular to the motion direction. Indeed,
the retina filter removes static contours and
enhances contours perpendicular to the motion
direction. As a result, in the log-polar
spectrum, the orientation related to the highest
energy also gives the motion direction. For the
detection of yawning or eyes closing, same
processing is done on each region of interest
(each eye and the mouth) [4]. A spectrum
analysis is carried out, but this time we are
looking for vertical motion only since eyes
closure or mouth yawning are related to such a
motion.
3.3 Eyes and mouth detection The
mouth is supposed to belong to the lower half of
the detected bounding box of the face.
Concerning the eyes, the spectrum analysis
in the region of interest is accurate only if
each eye is correctly localized. Indeed around
the eyes, several vertical or horizontal
contours can generate false detection (hair
boundary for example). The MPT toolbox proposes
an eye detector but it requires too much
computing time (frame rate of 22 fps), hence, it
has been discarded. We use another solution: eye
region is supposed to be the area in which there
are the most energized contours in the log-polar
domain. Assuming that the eyes are localized in
the two upper quarters of the detected face, we
use the retina output. The retina output gives
the contours in these areas and due to the fact
that the eye region (containing iris and eyelid)
is the only area in which there are horizontal
and vertical contours, the eye detection can be
achieved easily. We use two oriented low pass
filters: a horizontal low pass filter and a
vertical low pass filter and we multiply their
response. The maximum answer is obtained in the
area with the most horizontal and vertical
contours, that is the eye regions. The eye area
detection is performed at 30 frames per second.
3.4 Hypo-vigilance alarms generation Several
situations are supposed to be a sign of
hypo-vigilance: eyes closure detection, mouth
yawning detection and global head motion
detection.